Quantifying and mitigating turnover-induced knowledge loss
Reviewed by Greg Wilson / 2021-09-30
Keywords: Project Management, Turnover
Every time a developer leaves a project or is laid off, there's a chance that some knowledge about the project will leave with them. Pair programming and regular code reviews can ameliorate this by spreading understanding of the code base more widely throughout the team, but what if several people leave at once?
To analyze these risks, Rigby2016 borrows ideas from financial models of Value at Risk (VaR) to create a metric they call Knowledge at Risk (KaR). Since KaR may underestimate the risk of large losses (as financial models did in the run-up to the crash of 2008), they also define a second measure Expected Shortfall (ES) to estimate the shortfall resulting from large, rare events. They then use historical from Avaya and Chrome to model how many source files are likely to be abandoned each quarter (which they use as a proxy for knowledge loss) and find that the distributions are non-normal:
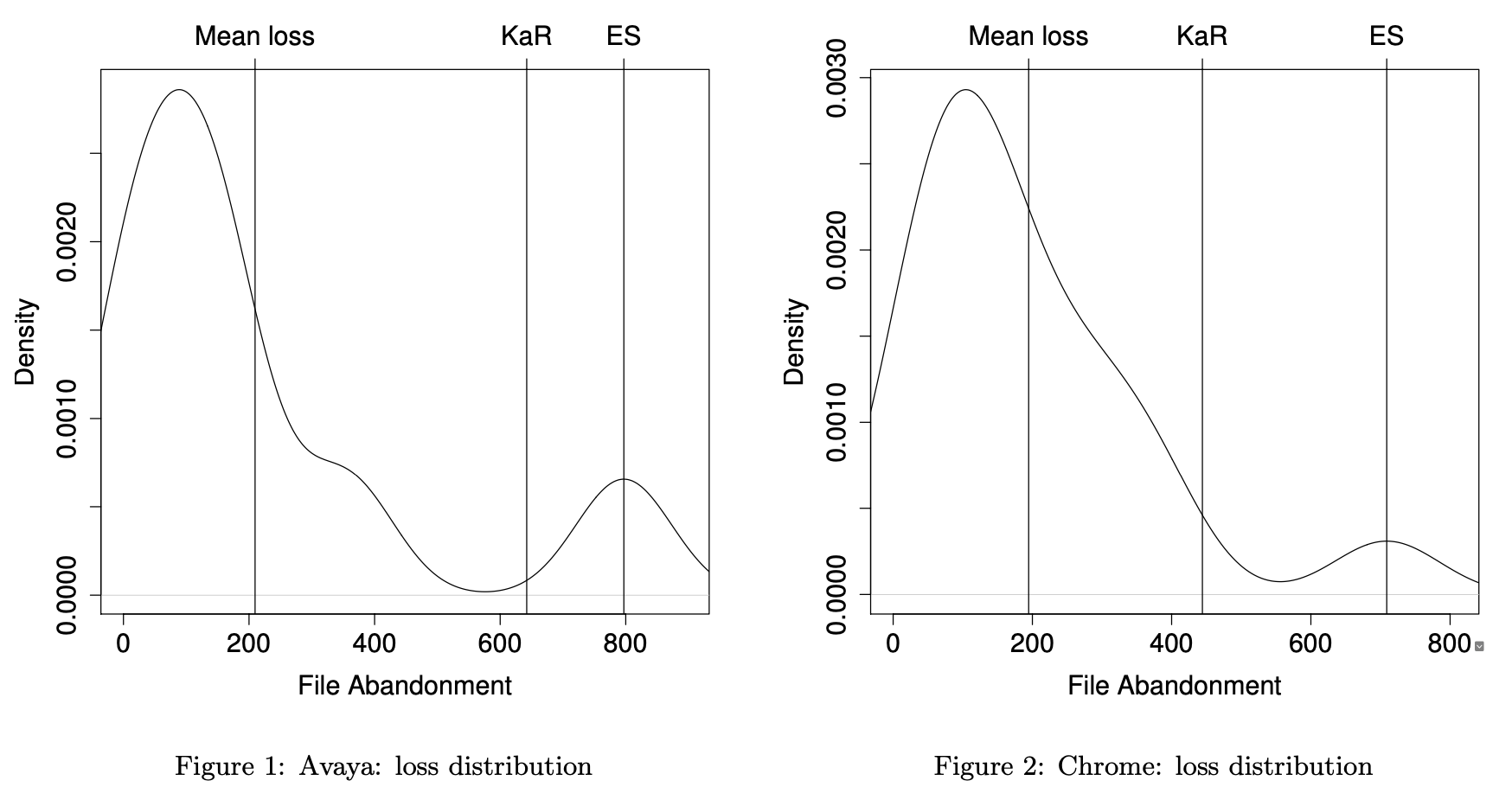
The authors used Monte Carlo simulation to model the "truck factor" for each project, i.e., to estimate how much knowledge would be lost if a randomly-chosen developer left the project without warning, then looked at how who takes over those abandoned files and found that:
Adding a new developer seems an obvious solution to file abandonment. However, on the projects we studied, the experts adopted the majority of abandoned files. In Figure 7 we can see that for Avaya 81% of developers who take over the maintenance of a file have at least one year and often many more years of experience. The corresponding number for Chrome is 54%, and only 16% of files are adopted by newcommers in their first quarter on the project.
Rigby2016 finishes by exploring whether information about who else has changed the abandoned files can be used to pick a good successor for the person who left. They then compared their recommendations against historical data about who actually went on to modify the abandoned file and found that they could reduce the median knowledge loss by about 25%.
I have reservations about how accurately file changes capture the distribution of knowledge in a project, but I don't have a better measure to offer, and even with those reservations I think this is a really interesting direction for research. If we can identify parts of a project that are at risk because knowledge about them is concentrated in one or a few heads, we can take steps to share that knowledge before someone is hit by a bus, wins the lottery, or finally decides that their ethics matter more to them than their stock options.
Rigby2016 Peter C. Rigby, Yue Cai Zhu, Samuel M. Donadelli, and Audris Mockus: "Quantifying and mitigating turnover-induced knowledge loss". Proceedings of the 38th International Conference on Software Engineering, 10.1145/2884781.2884851.
The utility of source code, as of other knowledge artifacts, is predicated on the existence of individuals skilled enough to derive value by using or improving it. Developers leaving a software project deprive the project of the knowledge of the decisions they have made. Previous research shows that the survivors and newcomers maintaining abandoned code have reduced productivity and are more likely to make mistakes. We focus on quantifying the extent of abandoned source files and adapt methods from financial risk analysis to assess the susceptibility of the project to developer turnover. In particular, we measure the historical loss distribution and find (1) that projects are susceptible to losses that are more than three times larger than the expected loss. Using historical simulations we find (2) that projects are susceptible to large losses that are over five times larger than the expected loss. We use Monte Carlo simulations of disaster loss scenarios and find (3) that simplistic estimates of the "truck factor" exaggerate the potential for loss. To mitigate loss from developer turnover, we modify Cataldo et al's coordination requirements matrices. We find (4) that we can recommend the correct successor 34% to 48% of the time. We also find that having successors reduces the expected loss by as much as 15%. Our approach helps large projects assess the risk of turnover thereby making risk more transparent and manageable.